cache的工作原理笔记
高速缓存存储器 Cache
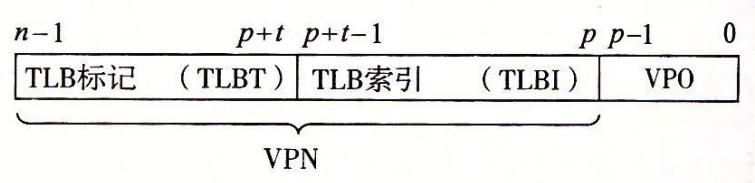
E = 1:直接映射高速缓存(direct-mapped cache)
E > 1:组相联高速缓存(set associative cache)
E = C/B:全相联高速缓存(fully associative cache)
存储器层次结构(memory hierarchy )
缓存命中(cache hit)
缓存不命中(cache miss)
写的情况要复杂一些。假设我们要写一个已经缓存了的字 w(写命中 ,write hit)。在高速缓存更新了它的 w 的副本之后,怎么更新 w 在层次结构中紧接着低一层中的副本呢?
最简单的方法,称为直写(write-through),就是立即将 w 的高速缓存块写回到紧接着的低一层中。虽然简单,但是直写的缺点是每次都会引起总线流量。
另一种方法,称为写回(write-back),尽可能地推迟更新,只有当替换算法要驱逐这个更新过的块的时候,才把它写到紧接着的低一层中。由于局部性,写回能显著地减少总线流量,但是它的缺点是增加了复杂性。高速缓存必须为每个高速缓存行维护一个额外的修改位(dirty bit),表明这个高速缓存块是否被修改过。
另一个问题是如何处理写不命中。一种方法,称为写分配(write-allocate),加载相应的低一层中的块到高速缓存中,然后更新这个高速缓存块。写分配试图利用写的空间局部性,但是缺点是每次不命中都会导致一个块从低一层传送到高速缓存。另一种方法,称为非写分配(not-write-allocate),避开高速缓存,直接把这个字写到低一层(主存)中。直写是非写分配的,写回是写分配的。
存储器层次解耦股中较低层的缓存更可能使用写回,而不是直写。
Cost of Cache Misses