CSAPP笔记--虚拟内存VM的地址翻译过程及页面置换算法
- 虚拟内存(VM) 部分
- TLB(Translation lookaside buffer)
- 端到端的地址翻译(具体过程)
* [TLB](#tlb) * [页表(Page Table)](#页表page-table) * [高速缓存(Cache)](#高速缓存cache) - 页面置换算法
虚拟内存(VM) 部分
TLB(Translation lookaside buffer)
A translation lookaside buffer (TLB) is a memory cache that stores the recent translations of virtual memory to physical memory.
TLB 是翻译后备缓冲器(translation lookaside buffer)的缩写,是 MMU 中关于 PTE 的小的缓存,目的是加速虚拟地址到物理地址的翻译
TLB 的一个例子
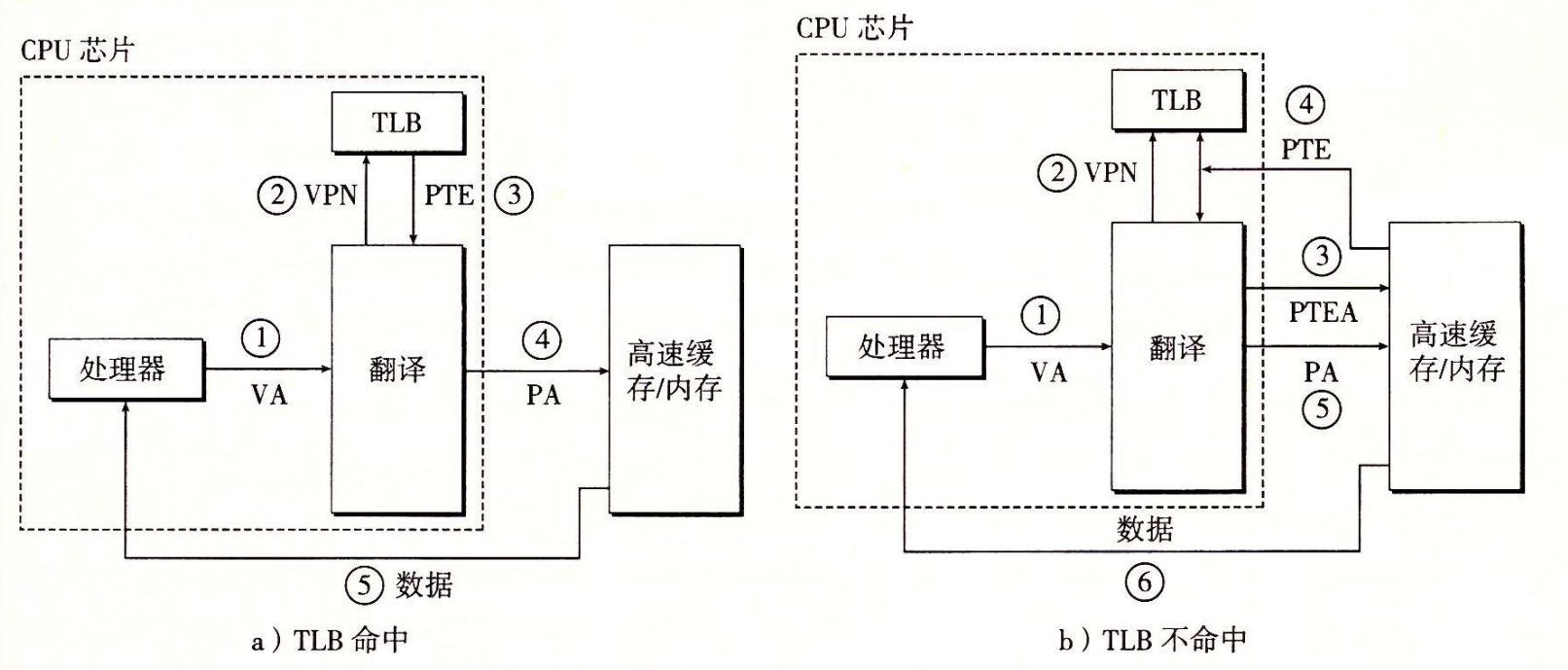
所有的地址翻译步骤都是在芯片上的 MMU(memory management unit) 中执行的
地址翻译步骤:
- CPU 产生一个虚拟地址
- MMU 从 TLB 中取出相应的 PTE(Page table entry)
- MMU 将这个虚拟地址翻译成一个物理地址,并且将它发送到高速缓存/主存
- 高速缓存/主存将所请求的数据字返回给 CPU
常用名词
| 缩写 | 描述 |
|---|---|
| $N = 2^n$ | 虚拟地址空间中的地址数量 |
| $M = 2^m$ | 物理地址空间中的地址数量 |
| $P = 2^p$ | 页的大小(字节) |
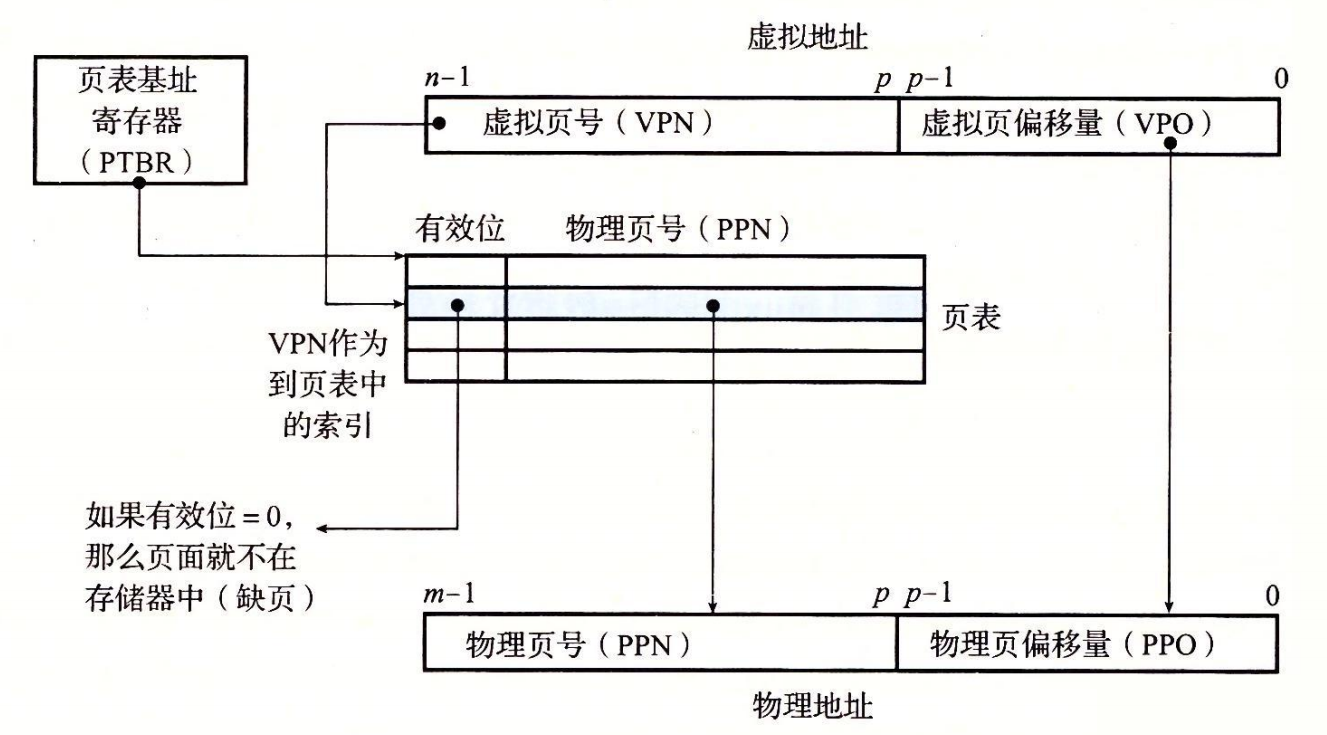
虚拟地址(VA)
| 缩写 | 英文全称 | 描述 |
|---|---|---|
| VPO | Virtual Page Offset | 虚拟页面偏移量(字节) |
| VPN | Virtual Page Number | 虚拟页号 |
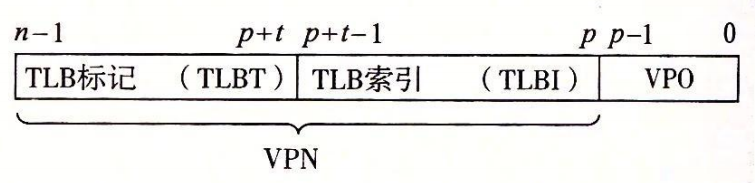
| TLBI | TLB Index | TLB 索引 |
| TLBT | TLB Tag | TLB 标记 |
物理地址(PA)
| 缩写 | 英文全称 | 描述 |
|---|---|---|
| PPO | Physical Page Offset | 物理页面偏移量(字节) |
| PPN | Physical Page Number | 物理页号 |
| CO | Cache Offset | 缓冲块内的字节偏移量 |
| CI | Cache Index | 高速缓存索引 |
| CT | Cache Tag | 高速缓存标记 |
Conceptually, a virtual memory is organized as an array of N contiguous byte-sized cells stored on disk.
Each byte has a unique virtual address that serves as an index into the array. The contents of the array on
disk are cached in main memory.
从某种意义上来讲,虚拟内存也是一种缓存,是内容在主存的缓存。
端到端的地址翻译(具体过程)
假设我们的系统是这样的:
- 内存是按字节寻址的。
- 内存访问是针对 1 字节的字的(不是 4 字节的字)。
- 虚拟地址是 14 位长的($n = 14$)。
- 物理地址是 12 位长的($m = 12$)。
- 页面大小是 64 字节($P = 64$)。
- TLB 是四路组相联的,总共有 16 个条目。
- L1 d-cache 是物理寻址、直接映射的,行大小为 4 字节,而总共有 16 个组。
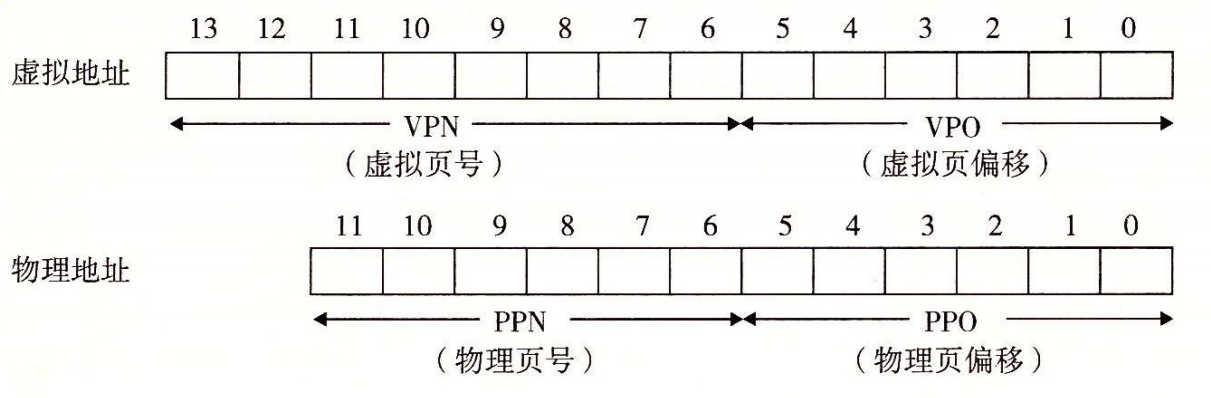
14 位虚拟地址(VA),12 位物理地址(PA)
每个页面是$2^6=64$Byte,所以虚拟地址和物理地址的低 6 位分别作为 VPO 和 PPO(这样偏移的话刚好能覆盖到地址)
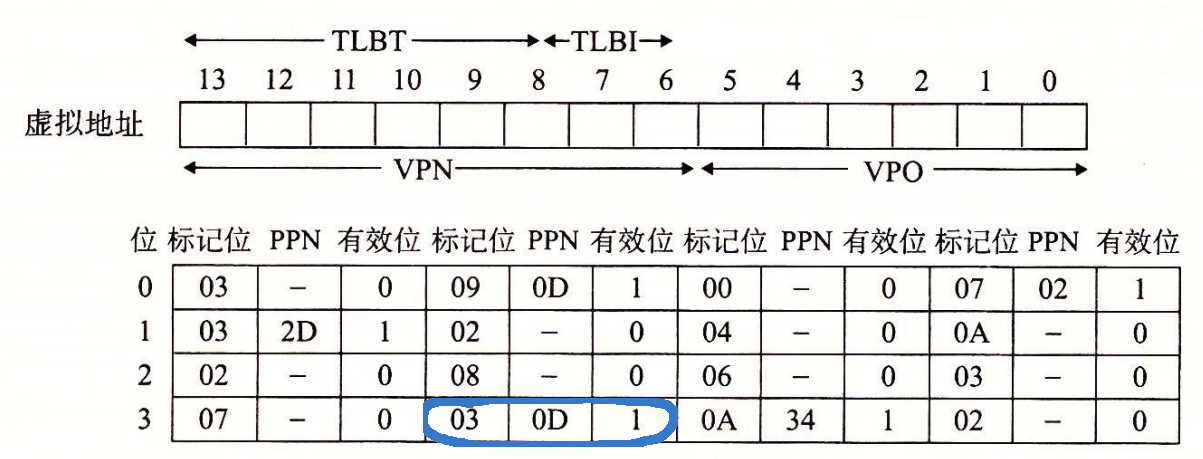
TLB
TLB 是利用 VPN 的位进行虚拟寻址的
TLB 是四路组相联的,TLBI 属于 VPN 的低两位($2^2=4$路),TLBT 属于 VPN 的高 6 位
页表(Page Table)
页表: 页表一共有$2^8 = 256$个 PTE(Page table entry),用索引它的 VPN 来标识每个 PTE
高速缓存(Cache)
每个块都是 4 Byte,低 2 位块偏移(Cache Offset),高 6 位标记(Cache Tag)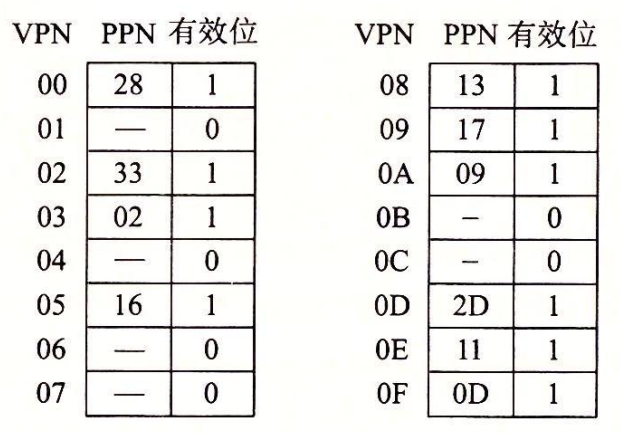
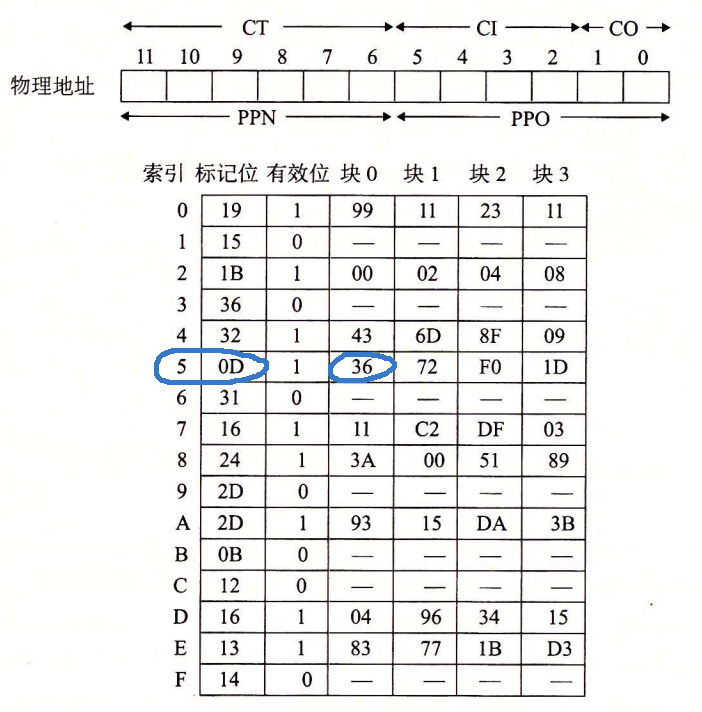
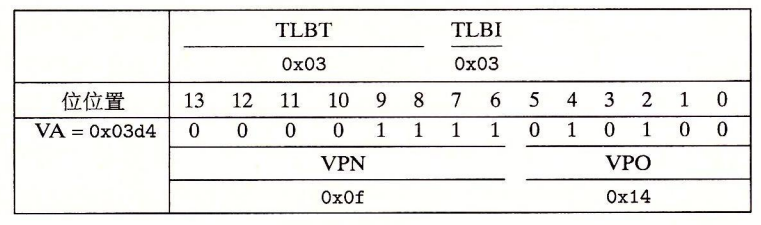
当 CPU 执行一条读地址 0x03d4 处字节的加载指令,我们来手工模拟一下接下来发生的过程。
MMU 从 0x03d4 取出 VPN(0x0F),TLB 从 VPN 取出 TLBI(0x03)和 TLBT(0x3),TLBT 与 index 为 2 的块匹配,取出 PPN(0x0D)返回 MMU (TLB 命中)
MMU 将来自 PTE 的 PPN(0x0D)和来自虚拟地址的 VPO(0x14)连接起来,形成物理地址 0x354
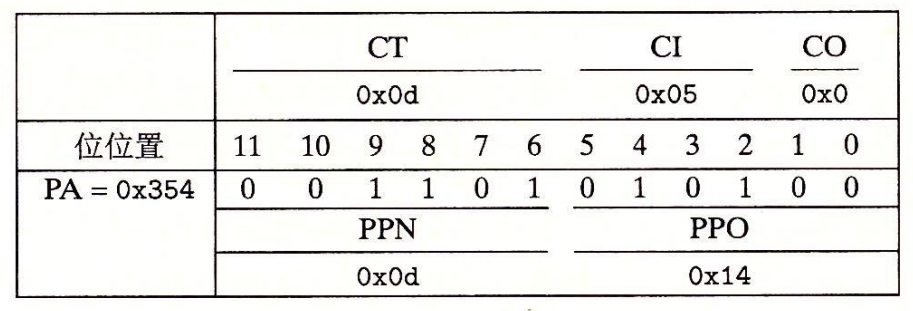
MMU 发送物理地址 0x354 给缓存,缓存从物理地址中抽取出缓存偏移 CO(0x0)、缓存组索引 CI(0x5)以及缓存标记 CT(0x0D)。
CI(0x5) 中的标记与 CT(0x0D) 相匹配,缓存命中,读出偏移量 CO 的字节 0x36,并返回给 MMU,MMU 把值传回 CPU
如果 TLB 不命中,PTE 无效,将会发生缺页中断(Page Fault),内核从磁盘调入合适的页面;另一种可能性是 PTE 是有效的,但是所需要的内存块在缓存中不命中
缺页中断(英语:Page fault,又名硬错误、硬中断、分页错误、寻页缺失、缺页中断、页故障等)指的是当软件试图访问已映射在虚拟地址空间中,但是目前并未被加载在物理内存中的一个分页时,由中央处理器的内存管理单元所发出的中断。
页面置换算法
最佳置换算法(OPT)
最佳(Optimal, OPT)置换算法所选择的被淘汰页面将是以后永不使用的,或者是在最长时间内不再被访问的页面,这样可以保证获得最低的缺页率。
但由于人们目前无法预知进程在内存下的若千页面中哪个是未来最长时间内不再被访问的,因而该算法无法实现。
(一个理论上的理想的算法)
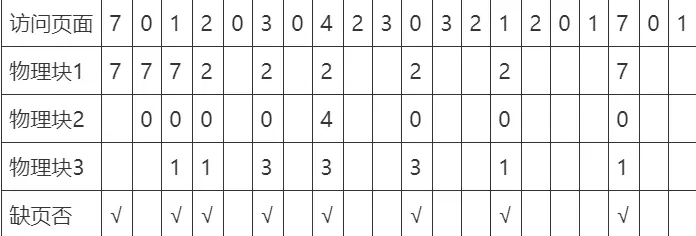
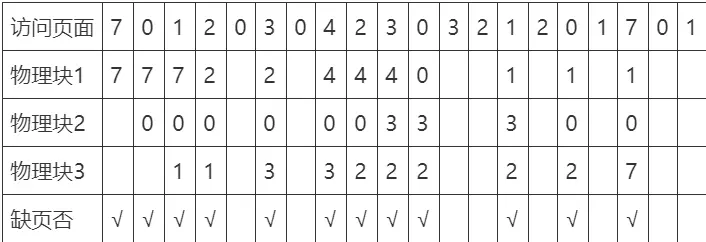
先进先出(FIFO)页面置换算法
队列的思想,把调入内存的页面根据先后次序链接成队列,设置一个指针总指向最早的页面
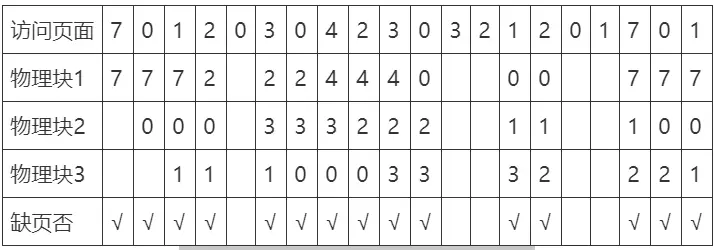
Belady Anomaly
FIFO 算法还会产生当所分配的物理块数增大而页故障数不减反增的异常现象,这是由 Belady 于 1969 年发现,故称为 Belady 异常
只有 FIFO 算法可能出现 Belady 异常,而 LRU 和 OPT 算法永远不会出现 Belady 异常
Belady’s Anomaly in Page Replacement Algorithms
这样的反复换入换出会导致页面调用的抖动(Thrashing)
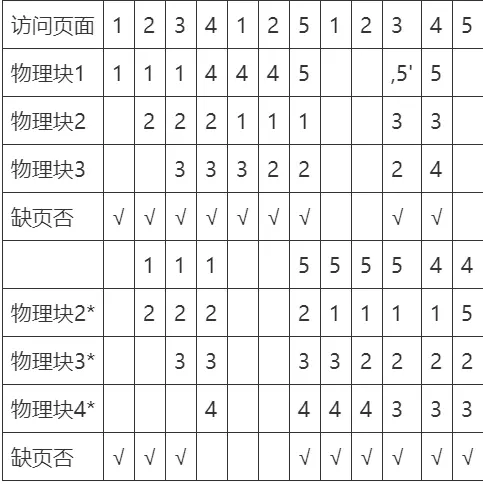
最近最久未使用(LRU = Least Recently Used)置换算法
选择最近最长时间未访问过的页面予以淘汰,它认为过去一段时间内未访问过的页面,在最近的将来可能也不会被访问。
时钟(CLOCK)置换算法
简单的 CLOCK 算法是给每一帧关联一个附加位,称为使用位。
当某一页首次装入主存时,该帧的使用位设置为 1;当该页随后再被访问到时,它的使用位也被置为 1。
对于页替换算法,用于替换的候选帧集合看做一个循环缓冲区,并且有一个指针与之相关联。
当某一页被替换时,该指针被设置成指向缓冲区中的下一帧。当需要替换一页时,操作系统扫描缓冲区,以查找使用位被置为 0 的一帧。
每当遇到一个使用位为 1 的帧时,操作系统就将该位重新置为 0;如果在这个过程开始时,缓冲区中所有帧的使用位均为 0,则选择遇到的第一个帧替换;如果所有帧的使用位均为 1,则指针在缓冲区中完整地循环一周,把所有使用位都置为 0,并且停留在最初的位置上,替换该帧中的页。
由于该算法循环地检查各页面的情况,故称为 CLOCK 算法,又称为最近未用(Not Recently Used, NRU)算法。
下一篇: 高速缓存(Cache)的工作原理